
기업용 LLM 파편화와 선택기준 | 매거진에 참여하세요
기업용 LLM 파편화와 선택기준
#LLM #역할 #선택 #가격 #효율성 #목적 #역할분리 #스위칭 #AI




왜 지금 ‘LLM 파편화(Fragmentation)’인가
2023~2024년에는 기업이 LLM을 고를 필요가 거의 없었다.
대부분 그냥 “GPT-4 쓰면 끝”이었다. 하지만 2025년에 들어오면서 상황이 완전히 달라졌다.
지금 SaaS/기업/스타트업들은 하나의 LLM만 쓰는 것이 아니라 여러 모델을 조합한다.
즉, LLM 선택이 UX, 비용, 기능, 리스크까지 전부 바꾸는 시대가 되었다.
이 현상을 “기업용 LLM 파편화”라고 부른다. 왜 이렇게 됐을까? 이유는 단순하다.
모델별 강점이 다르고, 비용 차이가 크며, 특정 작업에서 모델 편차가 명확해지고
국가별 규제/데이터 정책도 다르고, 오픈소스 모델이 급격하게 좋아졌기 때문이다.
이제 기업은 “하나의 모델로 모두 해결”하는 구조에서
사용 목적에 따라 LLM 포트폴리오를 구성하는 구조로 전환했다.
왜 LLM 파편화가 가속되는가
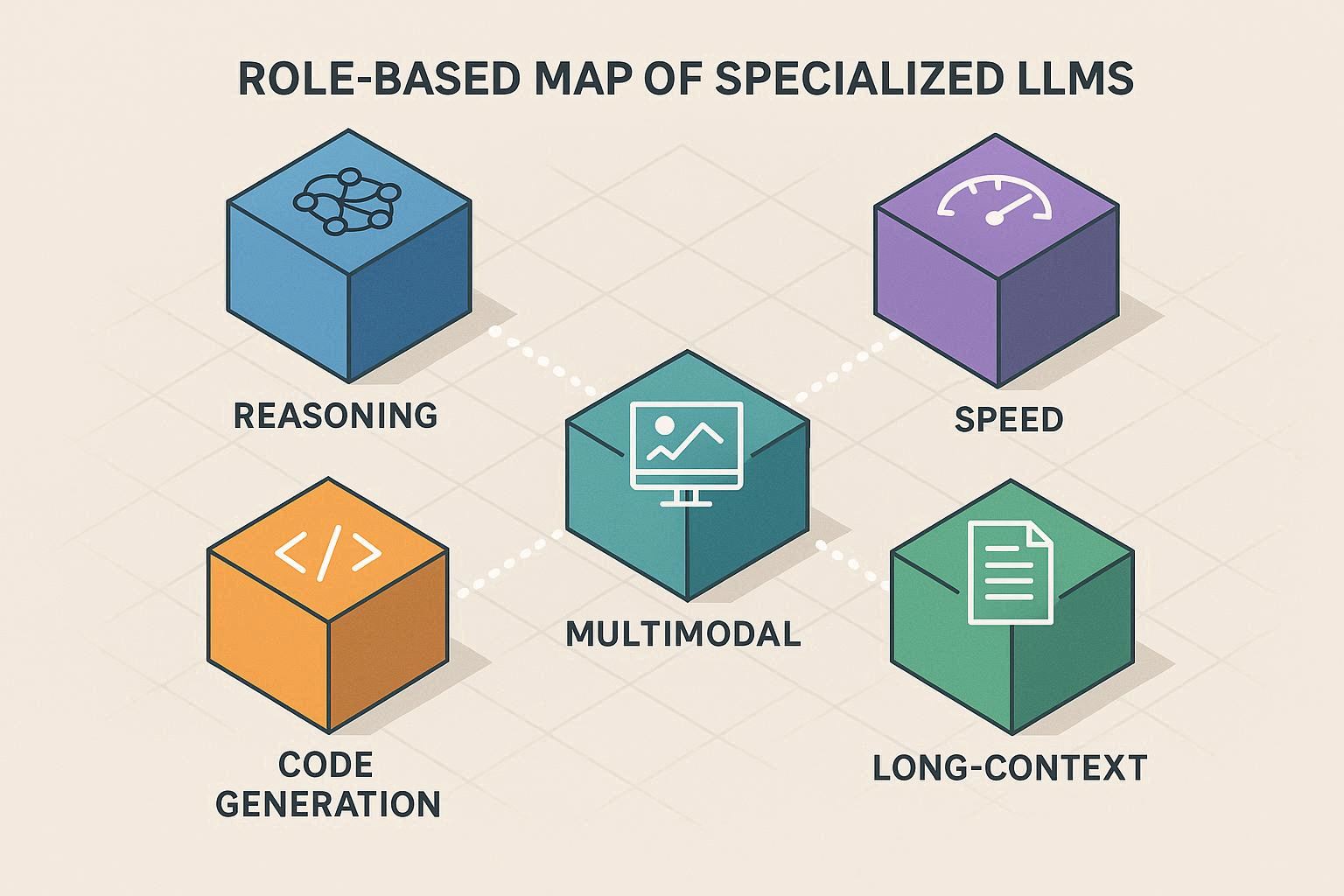
① 모델 전문화가 빠르게 진행됨
2025년의 상황은 이렇다.
- 텍스트 추론은 Claude가 강함
- 코드 생성은 GPT-5가 강함
- 속도는 Groq + 경량 모델이 압도적
- 멀티모달은 Gemini가 두각
긴 문맥/보고서 작업은 Mistral/Claude가 안정적
환각 적은 정밀 업무는 OpenAI ↔ Anthropic 박빙이며 오픈소스는 “대기업 PoC 수준”까지 올라옴
즉, 모델별 특징이 너무 명확해져서 단일 모델 선택이 비효율적이 되어버렸다.
② 비용 압박이 심해짐
GPU 가격과 LLM inference 비용은 엔터프라이즈의 실제 AI 도입에서 가장 큰 장애물이다.
예를 들어,
GPT-4/5 계열은 고성능이지만 비쌈
Gemini Flash는 저렴하지만 품질이 특정 영역에서는 아쉬움
오픈소스 Llama 계열은 실행 비용이 매우 저렴
기업은 자연스럽게 다음과 같이 움직인다.
“고품질이 필요한 작업만 비싼 모델을 쓰고
나머지는 경량/오픈소스로 돌리자.”
즉, 비용 기반의 모델 멀티 사용이 늘어나는 것.
③ 규제와 데이터 거버넌스 요구가 증가
기업은 AI를 도입하려면 데이터가 어디로 전송되는지 어떤 모델이 무슨 데이터를 처리했는지
로그가 어디에 쌓이는지 관리가 필요하다.
특히 금융/공공/헬스케어는 일부 데이터를 외부 모델로 전달할 수 없음.
→ 자연스럽게 사내 모델 + 클라우드 모델 혼합 구조가 된다.
④ LLM API가 API라기보다 ‘플랫폼’이 됨
2024년까지는 LLM이 하나의 API 느낌이었지만
2025년에는 “LLM API = 하나의 생태계”로 변했다.
- Tool API
- Memory API
- Agent API
- Autonomous Workflow API
- Multi-agent orchestration
즉, 모델 선택은 “가격과 성능”이 아니라 생태계 선택에 가까워졌다.
기업은 어떤 기준으로 LLM을 선택하는가
기업이 실제로 모델을 고를 때 고려하는 기준을
가장 현실적인 7가지로 정리해보면 아래와 같다.
① 품질: 모델의 능력
기업은 “벤치마크 점수”보다 실제 업무에서 다음을 본다.
- 추론 안정성
- 환각 빈도
- 수치 계산 능력
- 영문/국문/다국어 능력
- 멀티모달 능력
- 긴 문맥 처리
- 특정 도메인 처리 능력 (예: 금융/법률/의학/HR 등)
여기서 중요한 포인트는 모델별 편차가 실제 업무에서 체감될 정도로 명확하다는 것.
② 비용 구조: Token vs Output 기반
이제 비용은 단순히 “저렴한 모델 쓰자”가 아니다.
- Token input/output 요금
- 모델별 latency
- Context Window 비용
- API 호출 빈도
- 장기적으로 누적되는 사용량
- Operator/Agent 실행 비용
특히 에이전트 기반 서비스에서는 “작업 단위 가격(Task pricing)”이 중요해졌다.
③ 보안/데이터 정책
기업들은 다음 조건을 매우 엄격하게 본다.
- 고객 데이터 저장 여부
- on-prem 지원 여부
- 사내 VPC 배포 가능 여부
- 모델 내부 학습 사용 금지
- HIPAA/GDPR/ISMS 여부
- 국가별 데이터 위치
이 조건을 통과하지 못하면 품질이 뛰어나도 도입 불가능하다.
④ Latency & Speed (속도)
실제 업무에서는 속도가 매우 중요하다.
- 영업 자동화
- 고객 상담 자동화
- 운영 모니터링
- 내부 검색
이런 영역에서는 “생각 없이 빠르게 답하는 모델”이 중요하다.
Groq + Llama 계열이 여기서 가장 큰 존재감을 드러내고 있다.
⑤ Tool Use / Agent support
2025년에는 AI가 ‘대화’만 하면 의미가 없다. 행동할 수 있어야 한다.
따라서 기업은 다음을 본다.
- Tool 연결 구조
- Agent Orchestration 지원
- Computer Use(PC 조작)
- Memory persistence
- Fail-safe & Recovery
이 기준에서 OpenAI와 Anthropic이 크게 앞서 있다.
⑥ 모델의 지속성(roadmap)
기업은 “앞으로 이 모델이 안정적으로 유지되나?”를 항상 본다.
- 업데이트 주기
- 용도에 맞는 신규 모델 출시 여부
- 장기적인 API 정책
- 가격 인상 가능성
- 생태계 확장성
기업용 LLM에서는 “기술”만큼 “정책”이 매우 중요하다.
⑦ 개발자 경험 + 생태계”
개발자 경험은 실제로 도입 여부를 크게 좌우한다.
- 문서 품질
- 샘플 코드
- SDK 지원 범위
- 커뮤니티
- 디버깅 툴
- 로깅/모니터링 도구
즉, 모델이 좋다고 도입되는 것이 아니다.
개발자 경험이 좋으면 “도입 난이도”가 낮고 엔터프라이즈에서 빠르게 확산된다.
PM/기획자에게 중요한 LLM 선택 전략
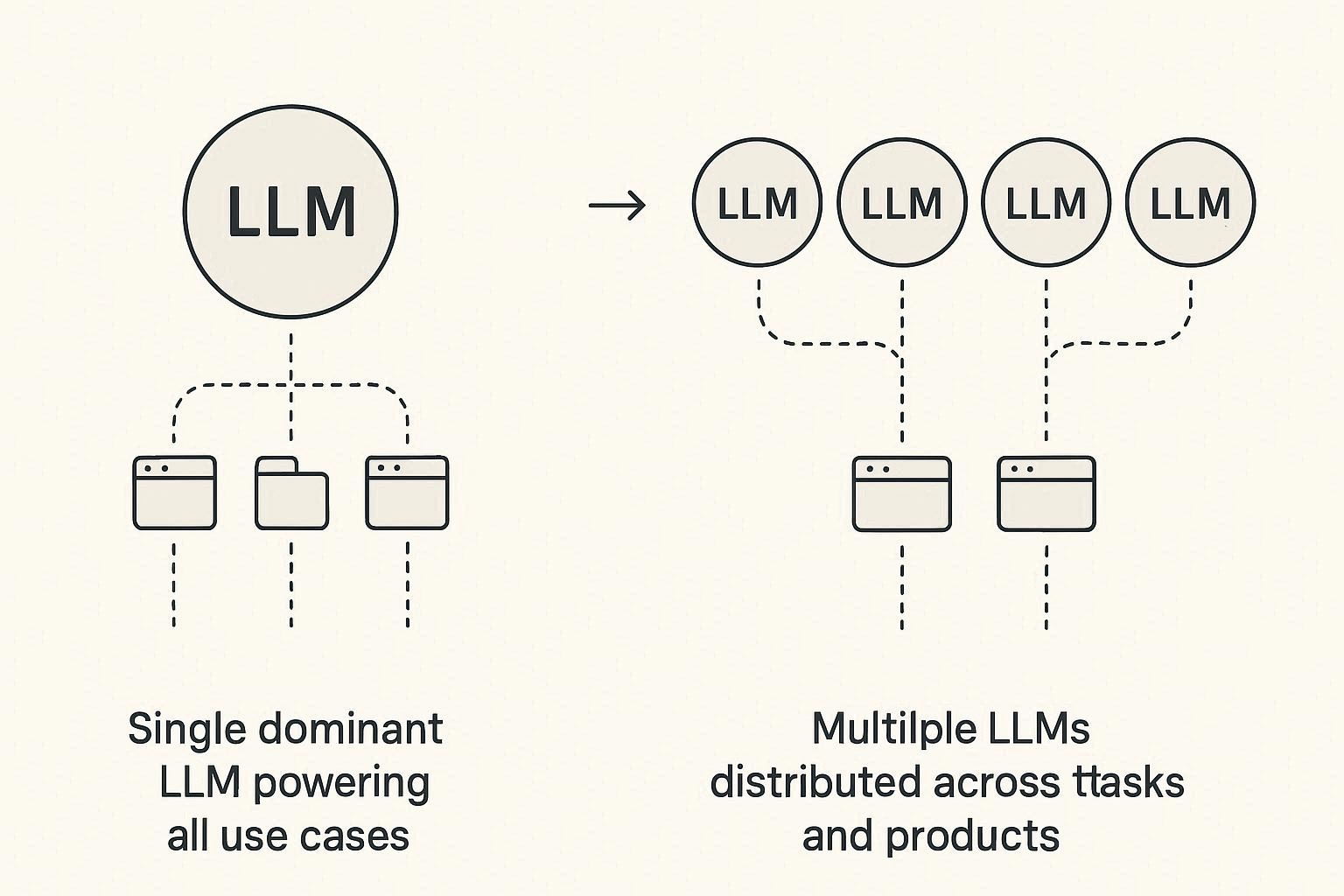
LLM 파편화 시대에 PM이 해야 할 일은 크게 4가지다.
① “모델별 역할 분리”가 필요하다
단일 모델로 제품 전부를 만드는 시대는 끝났다.
예를 들어:
- 검색 → 경량 모델
- 보고서 생성 → Claude/Mistral
- 코드 생성 → GPT-5
- 요약 → Gemini Flash
- 멀티모달 → Gemini Pro
- 대규모 문서 처리 → Claude/Mistral
- 실시간 응답 → Groq
기획자는 서비스의 각 기능에 어떤 모델이 최적화되어 있는지를 분석해 “모델 매트릭스”로 관리해야 한다.
② 모델 교체 가능성(Replaceability)을 반드시 고려해야 한다
LLM은 계속 업데이트된다. 2026년엔 모델 교체 주기가 3~6개월이 될 가능성이 높다.
따라서 처음부터 제품을 설계할 때
- 모델 간 API 추상화
- Switching 비용 최소화
- 중간 레이어 구축
이런 구조를 넣어야 한다.
③ UX는 ‘모델 선택 UI’가 아니라 ‘경험 일관성’을 목표로 해야 한다
사용자에게 “이 요청은 GPT-5로 보내고 저 요청은 Claude로 보낼까요?”
이런 걸 선택하게 하면 절대 안 된다.
LLM 파편화는 기술적인 문제지 UX 문제로 풀면 안 된다.
PM은 모델이 바뀌어도 UX가 동일하도록
내부 로직에서 자동 라우팅되도록 구조를 설계해야 한다.
④ 비용 시나리오를 기반으로 의사결정해야 한다
모델별로 가격 차이가 매우 크기 때문에 기획자가 초반에 “비용 예측 모델”을 만드는 것이 필수다.
- 하루 호출량
- 요청 평균 길이
- 작업 단위 가격
- 에이전트 실행 시간
이걸 추정해서
“이 서비스는 한 달에 얼마가 나오는지” 명확히 계산해야 한다.

- link_kakaolink_kakao_url
- link_operatorlink_operator_url
- link_investhelp@letspl.me
- link_ad_urllink_ad
